Criando um centralizador de logs para CloudWatch utilizando Logstash + AWS ElasticSearch Service
Uma das principais dificuldades em realizar troubleshooting em ambientes distribuídos é a coleta, organização e disponibilização de dados de forma centralizada! A ideia desse artigo é dar um norte para a consolidação desses dados, iniciando pelos logs do CloudWatch em ambientes AWS.
Criação do Cluster
Antes de dimensionar o cluster, calcule o volume de logs que será consolidado como base para o tamanho dos discos dos nós. A ideia aqui não é aprofundar muito nas questões de arquitetura da solução, mas dar uma visão geral do uso.
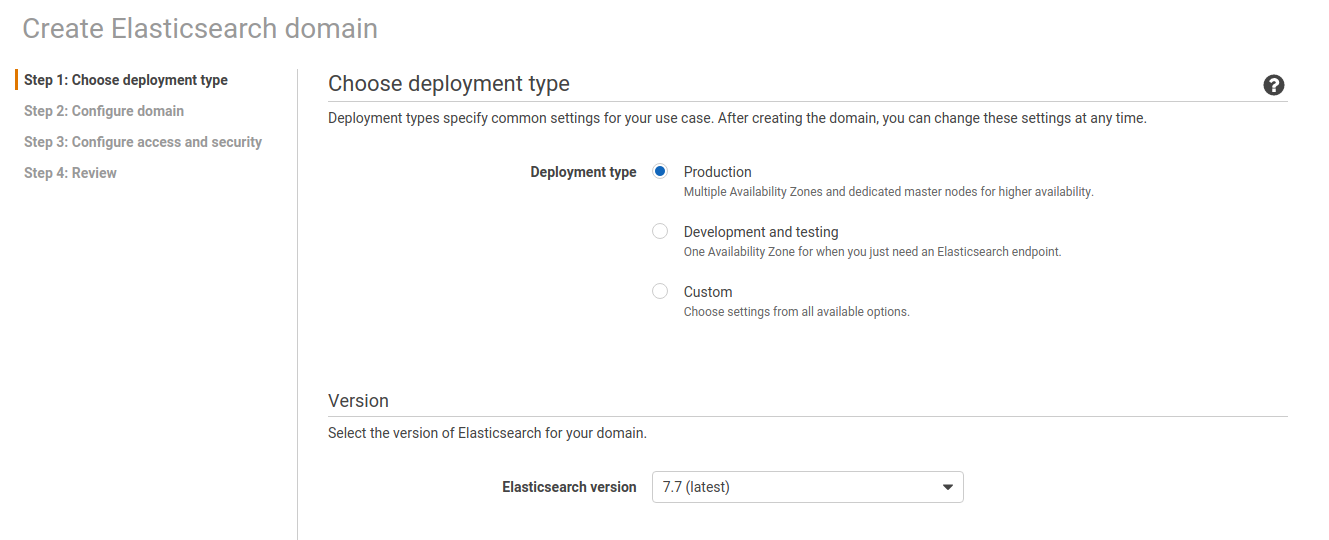
- Na console AWS, escolha o serviço “ElasticSearch Service”, clique em “Create a New Domain”.
- Step 1: Selecione o tipo de deployment de acordo com os requisitos de Alta Disponibilidade do seu ambiente.
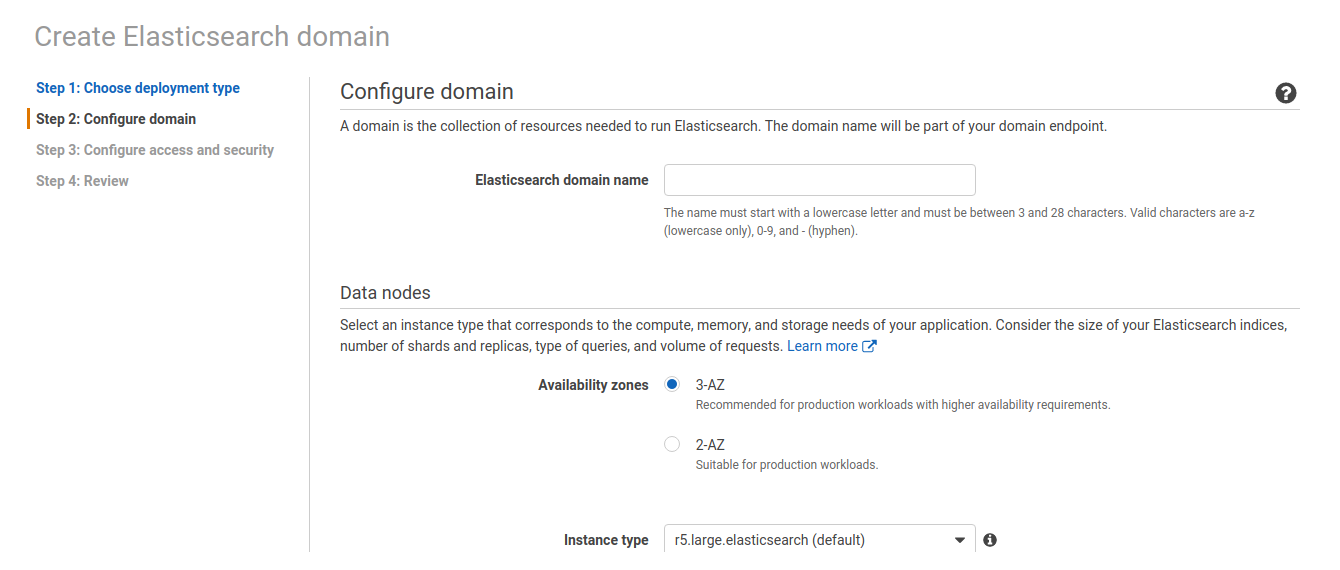
- Step 2: Na opção “Elasticsearch Domain Name”, digite um nome para identificação do Cluster. Esse nome também será o prefixo do Endpoint do cluster e será usado nos passos seguintes.
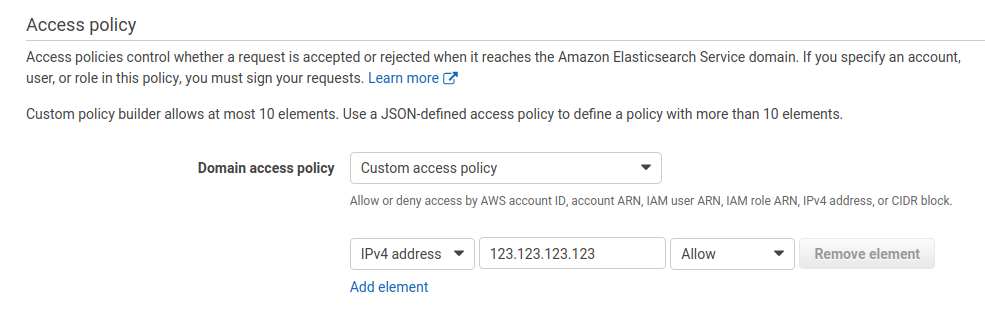
- Step 3: Configure access and security. Aqui para propósito de testes, vamos manter o Cluster como “público”, limitando o acesso via “Policy” (No exemplo, vamos considerar dois IPs, um da instância do Logstash e outro como nosso IP de saída pra internet) e setar algumas opções básicas, deixando o restante como Default. Nesse tutorial não iremos abordar as formas de autenticação disponíveis pois merece um artigo a parte.
Prossiga clicando em “Next”, depois “Confirm”. Aguarde o status do cluster mudar para “Active”.
Existem duas opções de envio de logs do CloudWatch para o Elasticsearch, o Stream de dados diretamente para o cluster ou a exportação para o S3. Lembrando que existem outras alternativas a todas as vantagens e desvantagens abaixo, mas a ideia é descrever os potenciais problemas de cada abordagem e não abordá-los a fundo.
Opção 1: Stream de logs para o ElasticSearch
Vantagens:
– Menor complexidade
– Stream em tempo real, automaticamente.Desvantagens:
– Todos os logs serão enviados para o mesmo Index (índice que será visualizado no Kibana para consulta aos logs), criado automaticamente pela Função Lambda.
– Não funciona com a autenticação HTTP (Opção Fine Granted Access + Master User).
– Não funciona com Clusters provisionados com acesso via VPC (ao invés de de Public Access).
Configuração:
– Acesse a console do “CloudWatch”
– Clique em “Log Groups” e selecione um dos loggroups que serão enviados para o ElasticSearch
– Clique no botão “Actions” -> “Stream to Amazon Elasticsearch Service”
– Neste caso, vamos escolher a opção “This Account” -> “Amazon ES cluster” e selecionar o nome do Cluster (Aquele definido no step da criação do Cluster).
– Selecione o Log Format desejado, clique em “next” e “Start Streaming”
– Caso você esteja fazendo o streaming pela primeira vez, a console vai criar automaticamente uma função Lambda para realizar a ingestão dos dados pelo Elasticsearch Service periodicamente, criando um índice com prefixo “cwl” (CloudWatch Logs).
Opcional:
Considerando redução de custos para o CloudWatch e também que os logs podem ter sua retenção gerenciada pelo próprio Centralizador de Logs, a sugestão é que seja aplicada uma política de retenção menor no CloudWatch. Neste exemplo foram criados os seguintes resquisitos:
- Os índices podem ser mantidos nos últimos 6 meses para instâncias.
- Foi aplicada uma regra em todos os LogGroups em todas as contas para alterar a retenção dos logs de “Permanente” para “180 dias”, visando manter somente os logs necessários e enviá-los ao centralizador de logs.
Exibir os loggroups e a retenção atual (Quando não há política de retenção, o campo Retention retorna como null:aws logs describe-log-groups — profile ${PROFILE} — region ${REGION} — output json — query ‘logGroups[*].{Name:logGroupName,Retention:retentionInDays}’Exemplo de aplicação de Retenção de Logs:Exibir os loggroups em formato texto, exibindo somente o nome do loggroup:aws logs describe-log-groups — profile ${PROFILE} — region ${REGION} — output text — query ‘logGroups[*].{Name:logGroupName}’OBS: por conta da paginação obrigatória, contas com listas muito grandes devem ser salvas manualmente em um arquivo de texto.Aplicar a retenção em todos os loggroups do arquivo de texto:for i in $(cat loggroups_${PROFILE}.txt); do aws logs put-retention-policy — log-group-name $i — retention-in-days 180 — profile ${PROFILE} — region ${REGION} ; done
Opção 2: Exportação de logs para o S3
Vantagens:
– Centralização dos logs enviados para o Cluster em um único Bucket ou em Buckets organizados por grupos de logs.
– Customização dos logs (parsing e filtering) e indices via Logstash.
– Liberação de acesso ao Cluster simplificada, tendo como único ponto de acesso a EC2 que estará rodando o Logstash.Desvantagens:
– Maior complexidade.
– Maior número de componentes para gerenciamento.
– A exportação dos logs não acontece automaticamente, ela deve ser feita manualmente pelo painel/cli e é feita considerando os registros gerados até aquela data/horário, sendo necessário automatizar esse processo à parte (Via AWs System Manager, shell script, ferramentas de automação em geral).
Nessa opção, podemos enviar todos os logs do CloudWatch (ou mesmo de logs locais de aplicação) para um bucket S3 e usá-lo como um repositório, enviando os logs para o Centralizador (Cluster do ElasticSearch) via Logstash.
O Logstash nesse caso, vai coletar os logs no S3 através de um plugin, aplicar eventuais filtros, definir um padrão de nome para a index e enviar os logs para o Cluster usando autenticação via Access Key/Secret Key.
Passo 1: Criar Bucket.
O bucket deve estar na mesma região do CloudWatch. Ai você me pergunta “Mas o bucket não é Global?”. Sim, é. Mas a região impacta no endpoint que será usado na configuração do LogStash. Após criar o bucket, selecione a opção “Properties” -> “Static Website Hosting”. Somente copie o endpoint mas não ative essa função. É o EndPoint que o plugin do Logstash identifica para envio dos logs.
Passo 2: Criar usuário com acesso ao S3
Crie um usuário no IAM com acesso programático e Full Access ao S3, baixe o arquivo de credenciais e guarde-o pois vamos usá-lo a seguir na configuração do pipeline do Logstash.
Passo 3: Exportar o LogGroup do CloudWatch para o S3:
Via console:
– Selecione o LogGroup desejado na console do CloudWatch
– Clique em “Actions” -> “Export Data to Amazon S3”
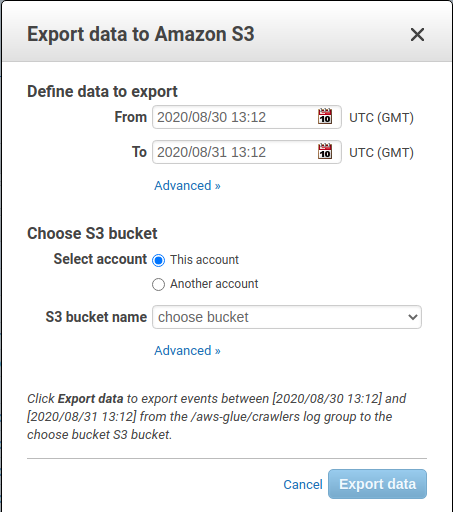
Selecione o período dos logs a serem exportados e o bucket de destino.
Via AWS Cli:
O processo via AWS Cli depende de alguns requisitos, como ele já estar configurado (credenciais, profiles,etc) além de somente aceitar o campo de data/horário dos logs no complicado formato de “milissegundos desde 01/01/1970. Fonte: Documentação AWS”, mas basicamente a linha de código para fazer o processo é:
aws logs create-export-task -log-group-name “caminho completo do loggroup” -from ‘1577847600000’ -to ‘1598583600000’ -destination “nome_do_bucket”- region us-east-1 - output text -profile my-profile
Para ajudar, existem sites que fazem essa conversão, como o CodeChi.
Caso queira listar todos os LogGroups de uma conta(ou profile) para exportar os logs em lote, execute o seguinte comando:
aws logs describe-log-groups -profile my-profile -region us-east-1 -output text -query ‘logGroups[*].{Name:logGroupName}’ > my_loggroups.txt
O Comando acima lista todos os LogGroups e salva em um arquivo.txt. Você pode executar um “|grep” para filtrar log groups que sigam um determinado padrão de nomenclatura. Após gerar a lista desejada, basta rodar outro comando para ler a lista e criar um Export Task para mandar todo o conteúdo para o Bucket criado:
for i in $(cat my_loggroups.txt);do aws logs create-export-task -log-group-name $i -from ‘1577847600000’ -to ‘1598583600000’ -destination “My_bucket” -region us-east-1 -output text -profile my-profile; done

Envio de Logs — Automatizado Com ajuda do Felipe Barbosa
Criação do processo de automatização para que os logs do CloudWatch sejam exportados para o bucket S3.
Pre-Requisito:
– Usuário IAM na conta AWS (é uma boa prática que tudo seja feito pelo usuário IAM, nunca utilizar a conta root)
– O usuário IAM deve ser autorizado para acessar os serviços da AWS para poder criar esta tarefa de automação.
Como Funciona?
Diariamente, em um determinado momento, uma regra de evento do CloudWatch aciona uma AWS Step Functions State Machine. A State Machine funciona com uma função AWS Lambda e ambos fazem a tarefa de exportação de logs do CloudWatch para S3.
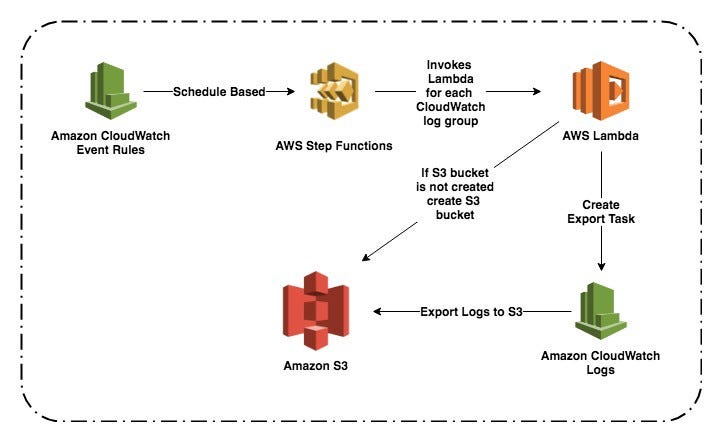
Criação — IAM Role
Criar uma função IAM e adicionar a seguinte política IAM inline:
{
“Version”: “2012–10–17”,
“Statement”: [
{
“Sid”: “VisualEditor0”,
“Effect”: “Allow”,
“Action”: [
“logs:CreateExportTask”,
“logs:DescribeExportTasks”,
“logs:CreateLogStream”,
“logs:DescribeLogGroups”,
“s3:PutBucketPolicy”,
“s3:CreateBucket”,
“s3:ListBucket”,
“logs:CreateLogGroup”,
“logs:PutLogEvents”
],
“Resource”: “*”
}
]}
Criação Função — Lambda
Criar uma função AWS Lambda e colocar este código na função lambda. Ao criar a função lambda, deve ser selecionado o Node.js 12.x e escolher a role criada anteriormente.
const AWS = require(‘aws-sdk’);
let cloudwatchLogsInstance = {};
let s3Instance = {};
let __region = ‘’;
function setRegion(_region) {
__region = _region;
}
function setInstance(_region) {
cloudwatchLogsInstance = new AWS.CloudWatchLogs({ region: __region });
s3Instance = new AWS.S3({ region: __region });
}
function getS3Buckets() {
return s3Instance.listBuckets({}).promise();
}
async function isS3BucketExists(bucketName) {
try {
const bucketsObject = await getS3Buckets();
const isBucketExists = bucketsObject.Buckets.find((bucket) => {
return bucket.Name === bucketName;
});
if (isBucketExists)
return true;
else
return false;
} catch (err) {
console.error(err);
}
}
async function createS3BucketAndPutPolicy(bucketName) {
try {
const _isS3BucketExist = await isS3BucketExists(bucketName);
if (_isS3BucketExist) {
console.log(‘s3 bucket exists’);
}
else {
await s3Instance.createBucket({
Bucket: bucketName
}).promise();
console.log(‘s3 bucket is created ‘, bucketName);
await s3Instance.putBucketPolicy({
Bucket: bucketName,
Policy: “{\”Version\”: \”2012–10–17\”,\”Statement\”: [{\”Effect\”: \”Allow\”,\
\”Principal\”: {\
\”Service\”: \”logs.”+ __region + “.amazonaws.com\”\
},\
\”Action\”: \”s3:GetBucketAcl\”,\
\”Resource\”: \”arn:aws:s3:::”+ bucketName + “\”\
},\
{\
\”Effect\”: \”Allow\”,\
\”Principal\”: {\
\”Service\”: \”logs.”+ __region + “.amazonaws.com\”\
},\
\”Action\”: \”s3:PutObject\”,\
\”Resource\”: \”arn:aws:s3:::”+ bucketName + “/*\”,\
\”Condition\”: {\
\”StringEquals\”: {\
\”s3:x-amz-acl\”: \”bucket-owner-full-control\”\
}\
}\
}\
]\
}”
}).promise();
console.log(‘s3 bucket policy is added’);
}
} catch (err) {
console.error(err);
}
}
function getDatePath(dateObj) {
const year = dateObj.getFullYear();
const month = dateObj.getMonth() + 1;
const date = dateObj.getDate();
return `${year}/${month}/${date}`;
}
function getLogPathForS3(logGroupName) {
if (logGroupName.startsWith(‘/’)) {
logGroupName = logGroupName.slice(1);
}
return logGroupName.replace(/\//g, ‘-’);
}
function wait(timeout) {
return new Promise((resolve) => {
setTimeout(() => {
resolve()
}, timeout)
})
}
function describeExportTask(taskId) {
let params = {
taskId: taskId
};
return cloudwatchLogsInstance.describeExportTasks(params).promise();
}
let waitErrorCount = 0;
async function waitForExportTaskToComplete(taskId) {
try {
const taskDetails = await describeExportTask(taskId);
const task = taskDetails.exportTasks[0];
const taskStatus = task.status.code;
if (taskStatus === ‘RUNNING’ || taskStatus.indexOf(‘PENDING’) !== -1) {
console.log(‘Task is running for ‘, task.logGroupName, ‘with stats’, task.status);
await wait(1000);
return await waitForExportTaskToComplete(taskId);
}
return true;
} catch (error) {
waitErrorCount++;
if (waitErrorCount < 3) {
return await waitForExportTaskToComplete(taskId);
}
throw error;
}
}
async function exportToS3Task(s3BucketName, logGroupName, logFolderName) {
try {
const logPathForS3 = getLogPathForS3(logGroupName);
const today = new Date();
const yesterday = new Date();
yesterday.setDate(today.getDate() — 1);
const params = {
destination: s3BucketName,
destinationPrefix: `${logFolderName}/${logPathForS3}/${getDatePath(new Date())}`,
from: yesterday.getTime(),
logGroupName: logGroupName,
to: today.getTime()
};
const response = await cloudwatchLogsInstance.createExportTask(params).promise();
await waitForExportTaskToComplete(response.taskId);
} catch (error) {
throw error;
}
}
function getCloudWatchLogGroups(nextToken, limit) {
const params = {
nextToken: nextToken,
limit: limit
};
return cloudwatchLogsInstance.describeLogGroups(params).promise();
}
exports.handler = async (event) => {
const region = event.region;
const s3BucketName = event.s3BucketName;
const logFolderName = event.logFolderName;
const nextToken = event.nextToken;
const logGroupFilter = event.logGroupFilter;
try {
setRegion(region);
setInstance();
await createS3BucketAndPutPolicy(s3BucketName);
let cloudWatchLogGroups = await getCloudWatchLogGroups(nextToken, 1);
event.nextToken = cloudWatchLogGroups.nextToken;
event.continue = cloudWatchLogGroups.nextToken !== undefined;
if (cloudWatchLogGroups.logGroups.length < 1) {
return event;
}
const logGroupName = cloudWatchLogGroups.logGroups[0].logGroupName;
if (logGroupFilter && logGroupName.toLowerCase().indexOf(logGroupFilter) < 0) {
// Ignore log group
return event;
}
await exportToS3Task(s3BucketName, logGroupName, logFolderName);
console.log(“Successfully created export task for “, logGroupName);
return event;
} catch (error) {
console.error(error);
throw error;
}
};
Criação — Step Function State Machine
O Step Function State Machine é uma coleção de estados que permite que você execute tarefas na forma de funções lambda, ou outro serviço, em sequência, passando a saída de uma tarefa para outro serviço.
Aba de serviços → Step Functions → clique em Get started
Selecionar Author from scratch → give state machine name → Selecionar Create a rule for me in IAM role e colocar o seguinte JSON in State machine definition (Put previously created lambda function ARN in JSON in State machine definition)→ click on Create state machine.
{
“StartAt”: “CreateExportTask”,
“States”: {
“CreateExportTask”: {
“Type”: “Task”,
“Resource”: “LAMBDA_FUNCTION_ARN”,
“Next”: “IsAllLogsExported”
},
“IsAllLogsExported”: {
“Type”: “Choice”,
“Choices”: [
{
“Variable”: “$.continue”,
“BooleanEquals”: true,
“Next”: “CreateExportTask”
}
],
“Default”: “SuccessState”
},
“SuccessState”: {
“Type”: “Succeed”
}
}
}
Criação — EventBridge
Nessa criação que será configurado o bucket, o diretório dos logs e tempo para execução do envio de logs para o S3.
* Services — EventBridge
* Criar Regra
* Definir nome
* Selecionar Programação
* Setar o tempo para o envio dos logs.
Em Selecionar Destino:
- Selecionar a Step Functions criada.
- Selecionar Constante (texto JSON) e colar a seguinte linha alterando os respectivos valores:
{ “region”:”us-east-1", “logGroupFilter”:”ecs-pet-ecare-ctv”, “s3BucketName”:”logstash-ecare-ctv-pet”, “logFolderName”:”exportedlogs” }
- Selecionar para criar uma nova função.
Após isso verificar se o S3 e o Kibana estão sendo atualizados.
Passo 4: Configuração do Logstash
A ideia nesse tutorial não é entrar a fundo na configuração do Logstash, então vamos apenas cobrir os passos padrão para uso do serviço e integração com o Elasticsearch Service.
Vamos criar uma instância EC2 com IP público, por segurança liberando o acesso via Security Group somente para nosso IP de internet. Você pode usar a AMI padrão da AWS e instalar o Logstash. Crie o arquivo “/etc/yum.repos.d/logstash.repo” com o seguinte conteúdo:https://tnsilva.medium.com/media/d2b5ce4881e4bfb3e640029952b0d151
Faça a instalação do serviço e do plugin de integração com o S3:
yum update
yum install logstash -y
/usr/share/logstash/bin/logstash-plugin install logstash-input-s3
Nesse exemplo, vamos modificar o arquivo “/etc/logstash/conf.d/examples.conf” com as configurações base abaixo, mas o ideal é segmentar as configurações por pipelines através do arquivo “/etc/logstash/pipelines.yml” apontando para cada arquivo de aplicação na pasta “conf.d”, mas foge do escopo desse artigo.
Exemplo do arquivo “examples.conf” do logstash:https://tnsilva.medium.com/media/2885806589858e5f7871e7835fc3fbc2
Reinicie o serviço e verifique os logs (/var/log/logstash/logstash-plain.log). Em caso de sucesso, o log vai retornar uma linha semelhante a essa:
[INFO ][logstash.inputs.s3 ] Using default generated file for the sincedb {:filename=>”/var/lib/logstash/plugins/inputs/s3/sincedb_f9fd262d301e48d33acd43a4d59e4660"}
O SinceDB armazena o histórico dos arquivos S3 já processados pelo Logstash. Caso a opção “watch_for_new_files” esteja na configuração, o Logstash faz uma comparação entre a listagem de arquivos no bucket e o que consta no SinceDB e processa os arquivos mais recentes.
Pronto! Usando essa base, você consegue redirecionar basicamente qualquer tipo de logs do CloudWatch ou ainda usar o Logstash para consumo de logs via outras fontes como Servidores Web, Bancos de dados, etc através do FileBeat ou o FluentD.